

Le projet Erygma est une proposition de solution et de questionnement face aux problèmes soulevés par le projet de recherche “Géologie critique des datasets”.
Dans le domaine de la data science, on trouve encore des méthodologies de documentation très variées, qui témoignent d'un manque de cadre sur ces pratiques. Alors, Gebru et al. (2020) proposent les Datasheets for Datasets, des fiches techniques présentes au sein de chaque dataset, permettant d'en retrouver facilement les motivations, les données qui le composent et les préconisations d'usage, dans le but d'une utilisation plus adaptée pour limiter les erreurs et leur utilisation à des fins répréhensibles.
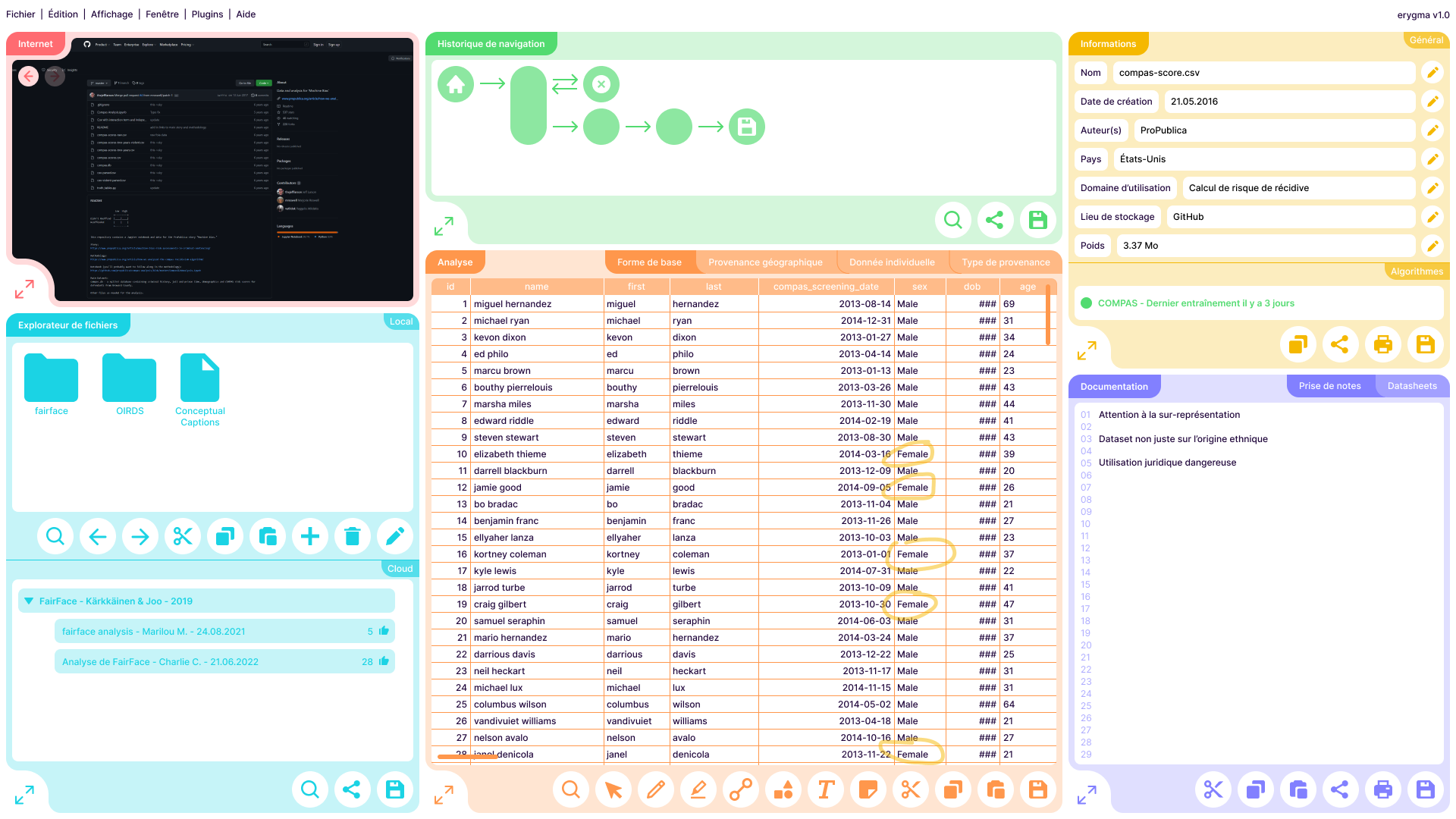
Capture d'écran du logiciel. De gauche à droite et de haut en bas : un navigateur internet pour la recherche du dataset (rouge), un historique de navigation permettant de documenter le trajet de recherche (vert), les informations générales du dataset (jaune), un explorateur de fichiers en local et en cloud (bleu), l'interface d'analyse (orange) et l'interface de documentation (violet).
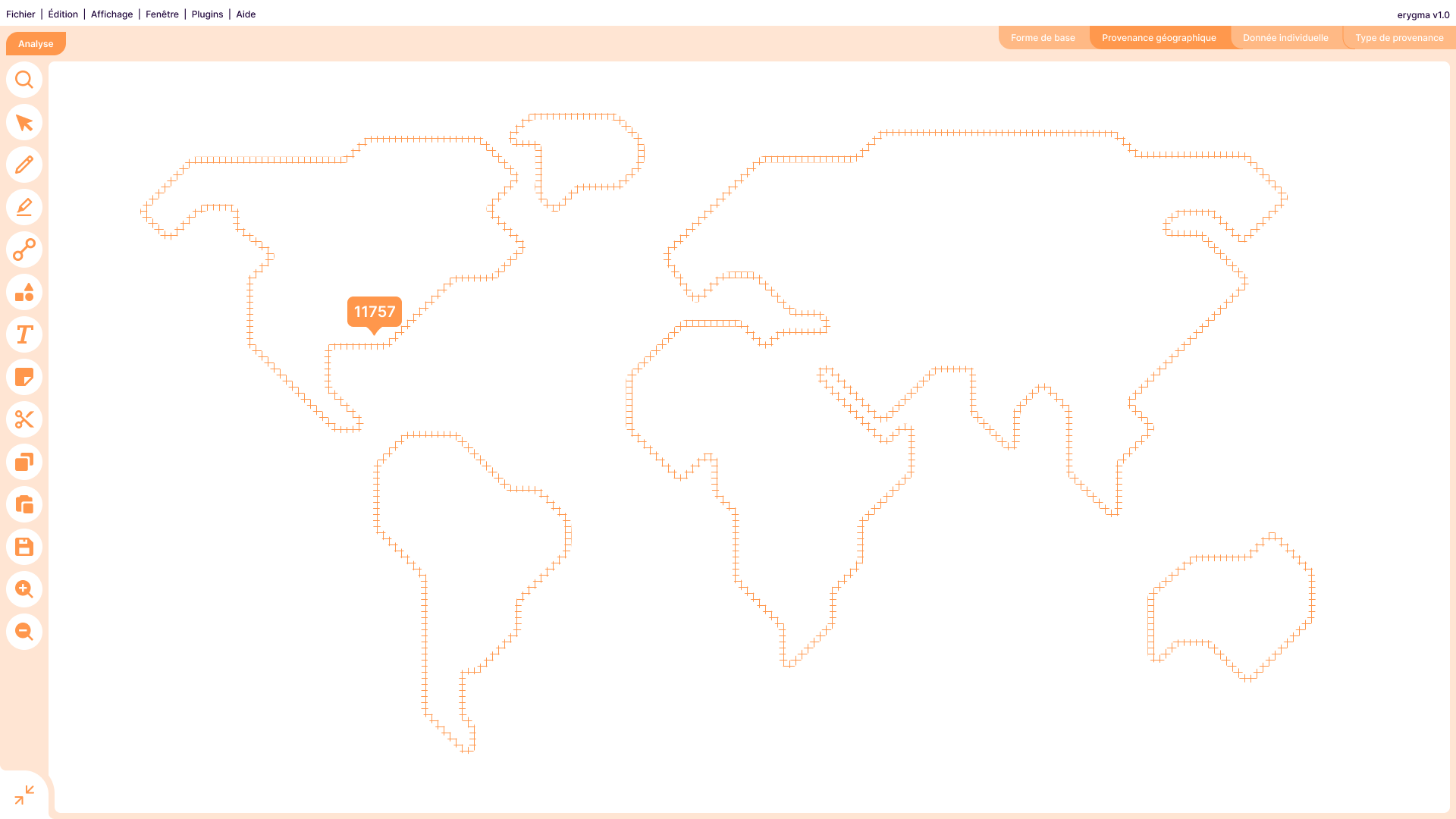
Le logiciel offre différentes possibilités de visualisation pour la provenance des données.

Photo du logiciel lors de ma présentation de projet avec mise en relation des Datasheets.
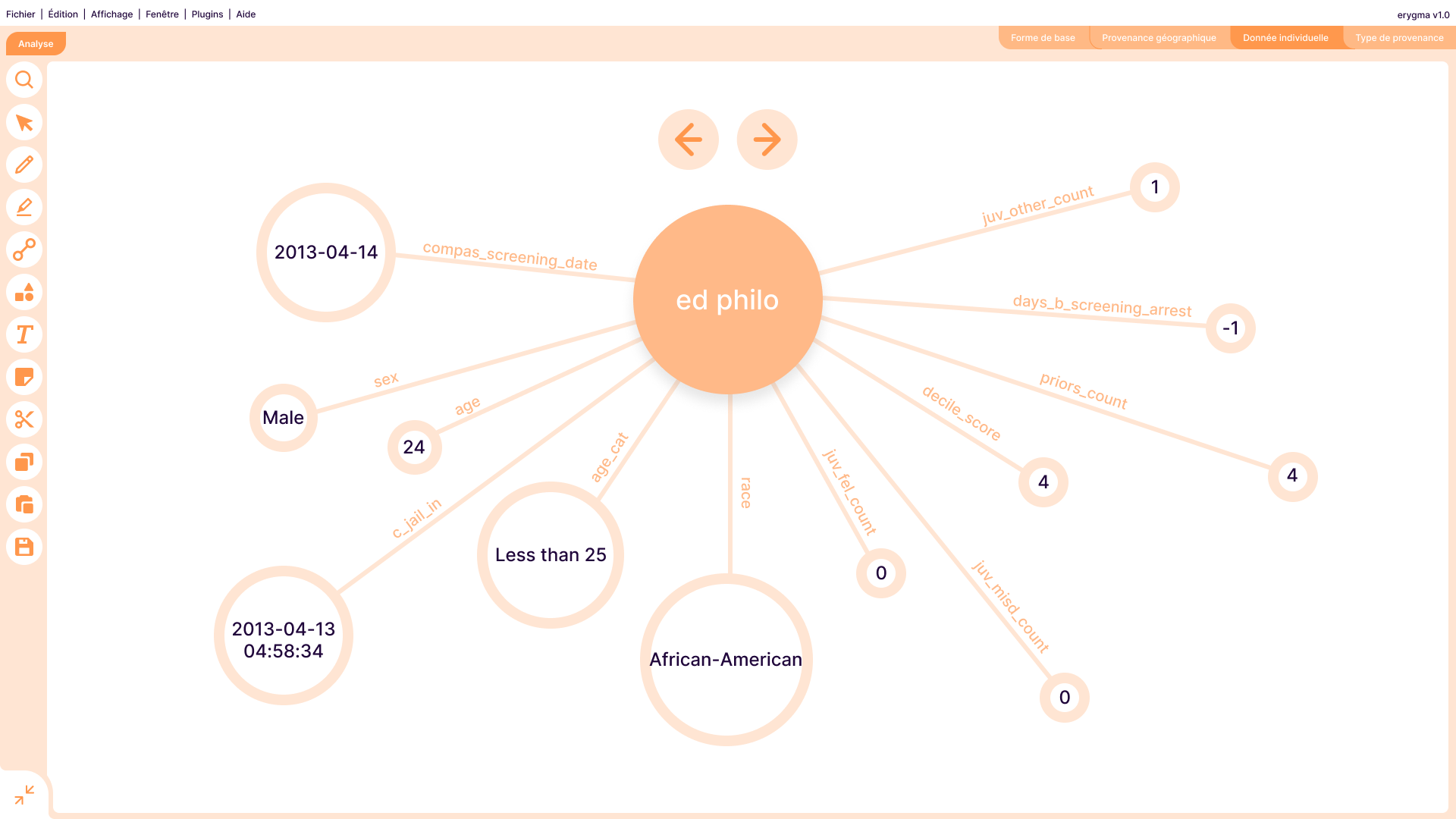
Visualisation d'une donnée particulière.
En me basant sur la pratique des Datasheets, j'ai cherché à concevoir un outil permettant la recherche, l'analyse et la documentation partagée des datasets. Cet outil prend la forme d'un logiciel, utilisable par n'importe quelle partie prenante du monde de l'IA : data scientist, chercheur.euse, journaliste, juge, … Il permet de rechercher, de visualiser, d'annoter et de documenter un dataset, selon des critères plus sociaux que techniques : par exemple, relever une sous-représentation potentiellement problématique, et avertir que ce dataset doit être utilisé dans des cas très précis pour éviter une discrimination.
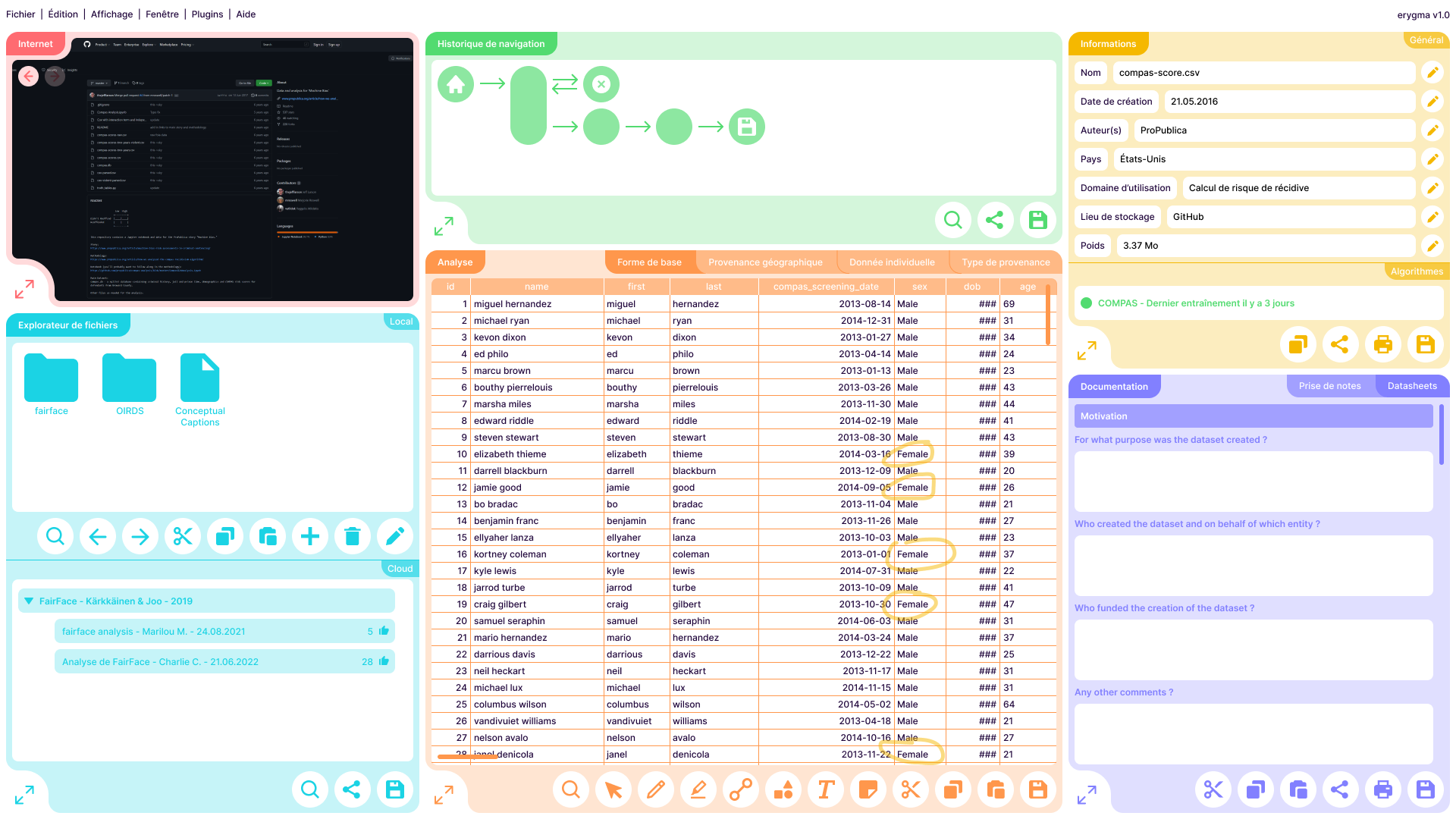
Reprenant les pratiques et méthodes des Datasheets, l'interface de documentation (en bas à droite) propose des questions d'aiguillage permettant à l'utilisateur.ice de donner un maximum de contexte au dataset.
