

Ce travail de recherche a été mené en collaboration avec le médialab Sciences Po, laboratoire de recherche interdisciplinaire réunissant sociologues, ingénieur.e.s et designers et menant des recherches thématiques et méthodologiques exploitant et interrogeant la place prise par le numérique dans nos sociétés. Ce travail prend sa place au sein du programme de recherche "Algoglitch : comment voulons-nous être calculés ?", mené au sein du médialab par, notamment, Pauline Gourlet, Donato Ricci et Axel Meunier.

Édition du mémoire avec schéma de recherche.
Sur toutes les bouches et dans tous nos usages depuis la fin des années 2000, l'intelligence artificielle est un sujet d'étude bien plus ancien que ce que l'on croit. Mais si l'on parle autant d'intelligence artificielle aujourd'hui, c'est parce que la fin des années 2000 marque le croisement de deux évolutions technologiques facilitant la collecte, le traitement et l'organisation d'immenses quantités de données, regroupées en jeux appelés datasets. Ces datasets permettent la réalisation d'une approche toute autre de l'intelligence artificielle, qui n'avait pu faire ses preuves jusque là : l'apprentissage automatique, ou machine learning. Cette approche consiste à entraîner les algorithmes avec des milliers, voire des millions d'exemples, pour qu'ils soient en mesure de faire le lien entre ceux-ci, permettant de créer des règles appliquables à toute nouvelle entrée inconnue.
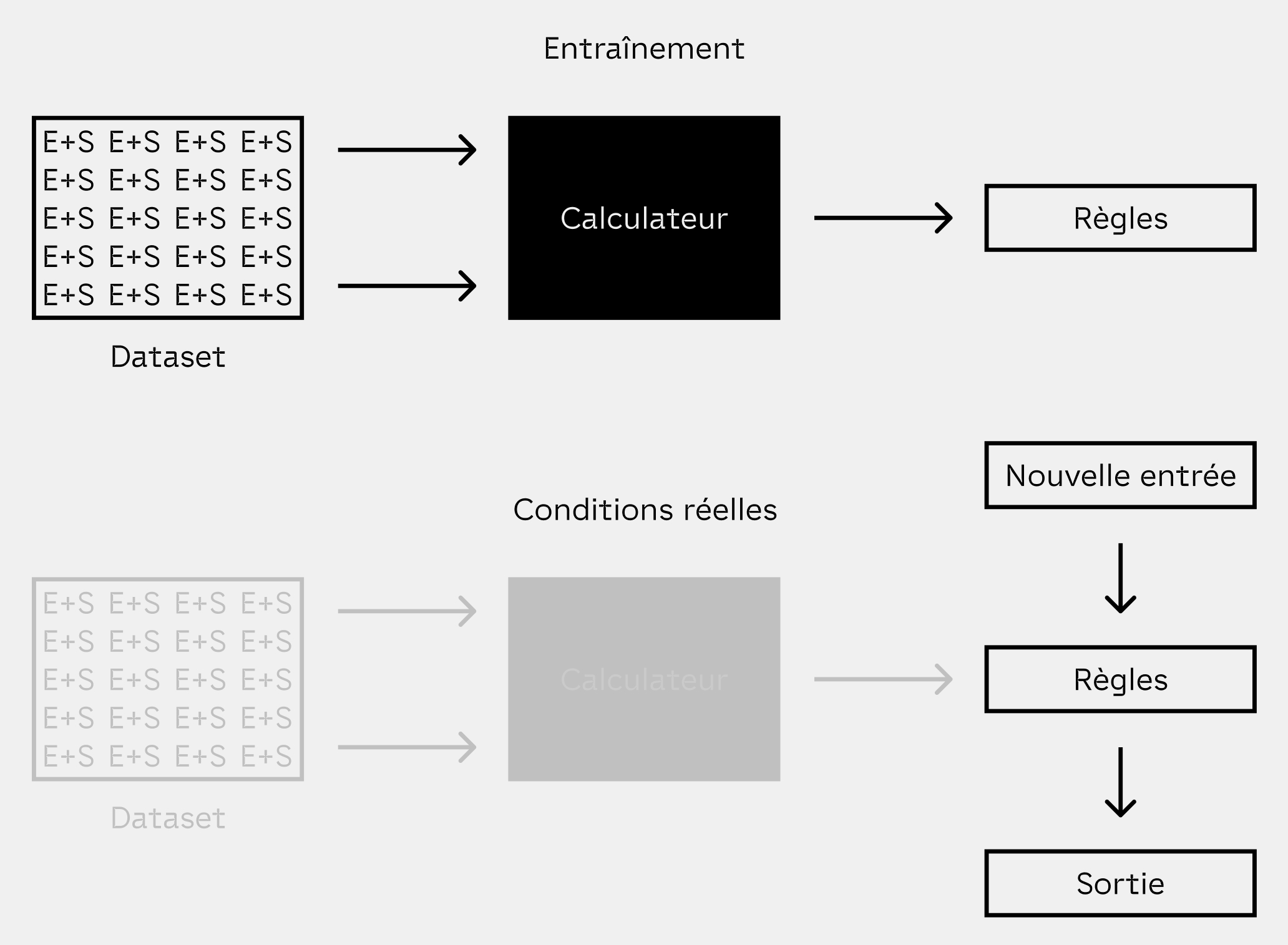
Le machine learning et ses phases d'entraînement et de production.

Expérimentation interactive de visualisation des datasets.
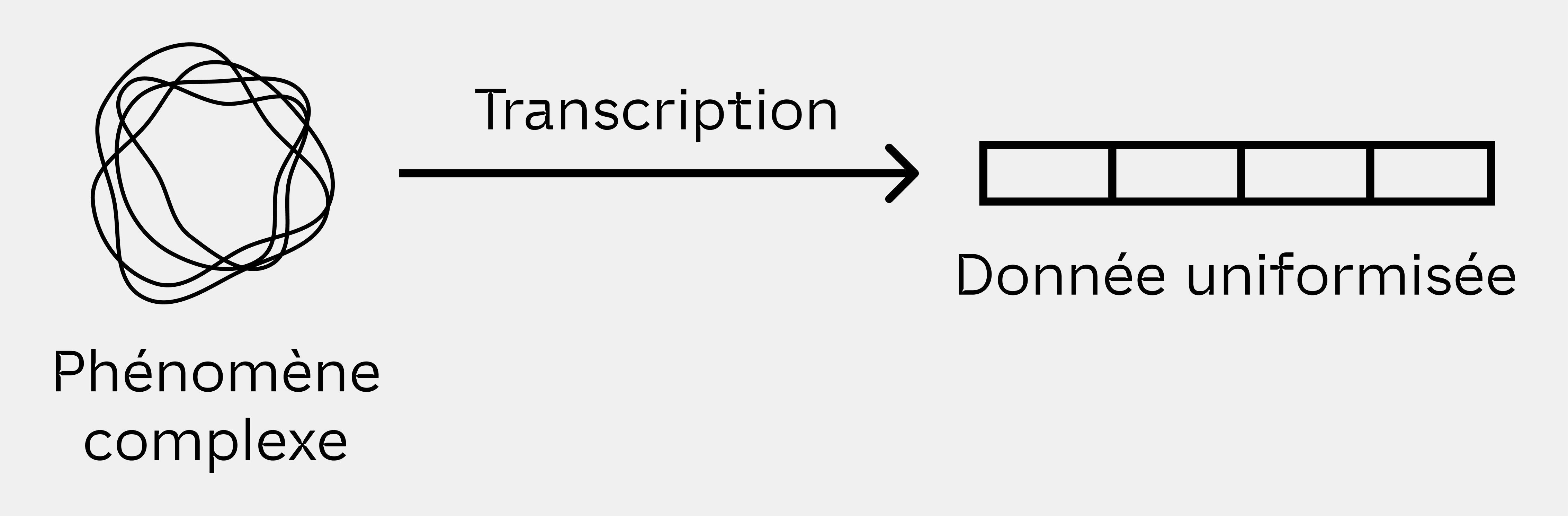
La collecte de données brutes, une uniformisation qui trahit le phénomène.
Aujourd'hui, le problème auquel je m'intéresse est le suivant : le machine learning est utilisé dans des domaines qui lui offrent du pouvoir, facilitant la prise de décisions importantes. Ces décisions doivent être expliquées pour en limiter la dépendance : car elles ne sont pas comprises, elles peuvent êtres vues comme fiables ou objectives. Pourtant, les algorithmes prenant ces décisions sont entraînés par des jeux de données construits par l'humain, et qui incluent donc nécessairement des biais. Les datasets sont des objets situés, résultant de processus de sélection contextualisés. Alors, ces classifications informatiques risquent de se muer en classifications sociales, politiques en cas d'une utilisation non adaptée de ces jeux de données.
Alors, au lieu de chercher à retirer des datasets ces biais et cette contextualité, il serait peut-être plus judicieux de les prévenir et de les documenter, pour éviter les utilisations non adaptées et potentiellement problématiques.

Ce travail de recherche a aussi été l'occasion de proposer un travail d'édition.